NFL data — One ring to rule them all
I’m a great fan of football, and the athletic performances brought to us by NFL on “Any Given Sunday”. However, a league with 32 teams is often hard to visualize...


... that is why we will select a few epic seasons here, focusing on champions and top performing teams of that particular year.
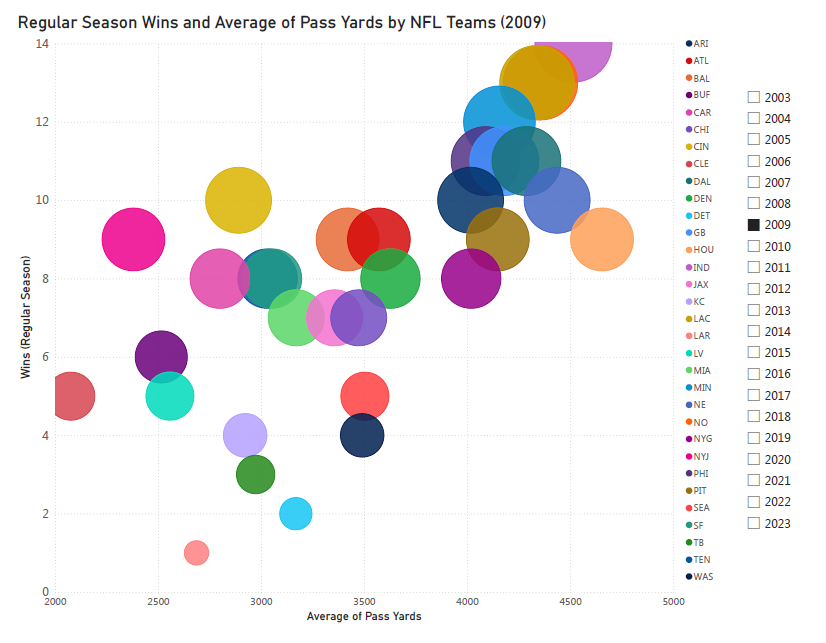
Let’s start out with the 2009 season, when the Vince Lombardi Trophy found a new home in The Big Easy.
Let’s start out with the 2009 season, when the Vince Lombardi Trophy found a new home in The Big Easy.
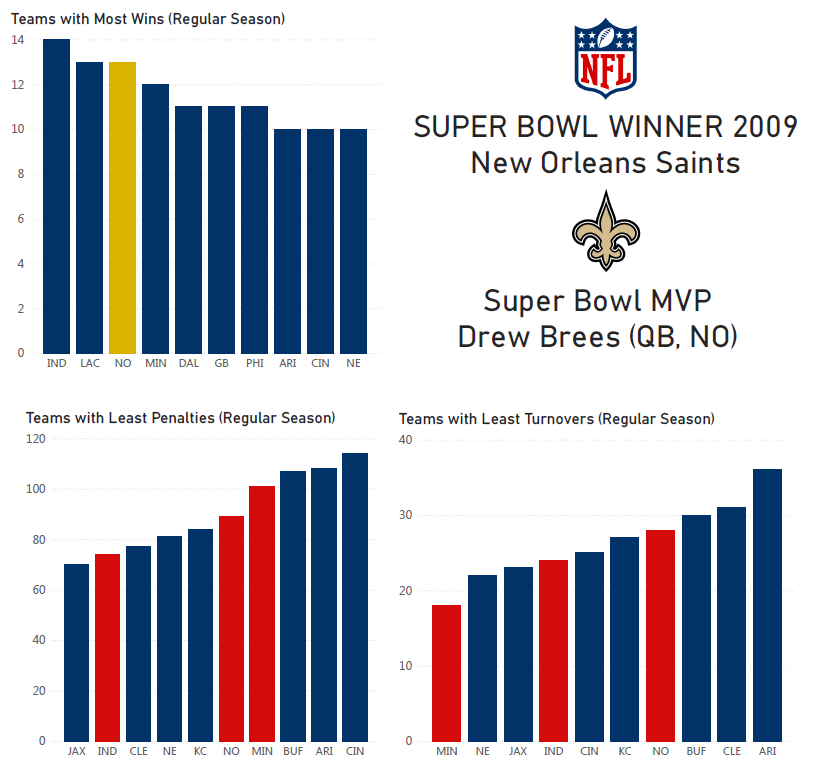

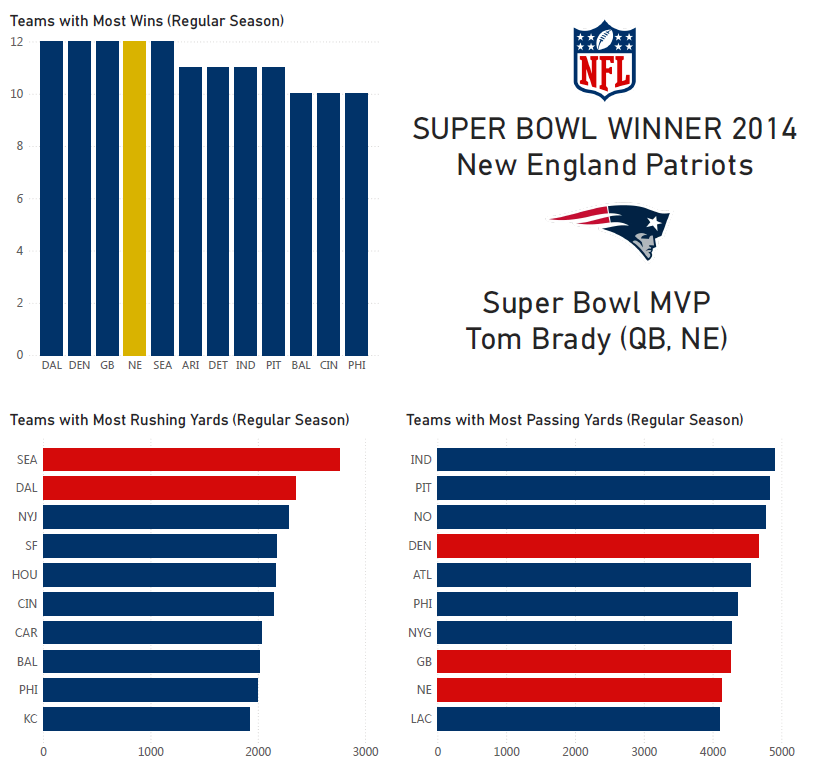
Business as usual for the legendary head coach and quarterback duo of Bill Belichick and Tom Brady. The 2014 season marked the fourth of the total six Super Bowl wins for the New England dynasty.
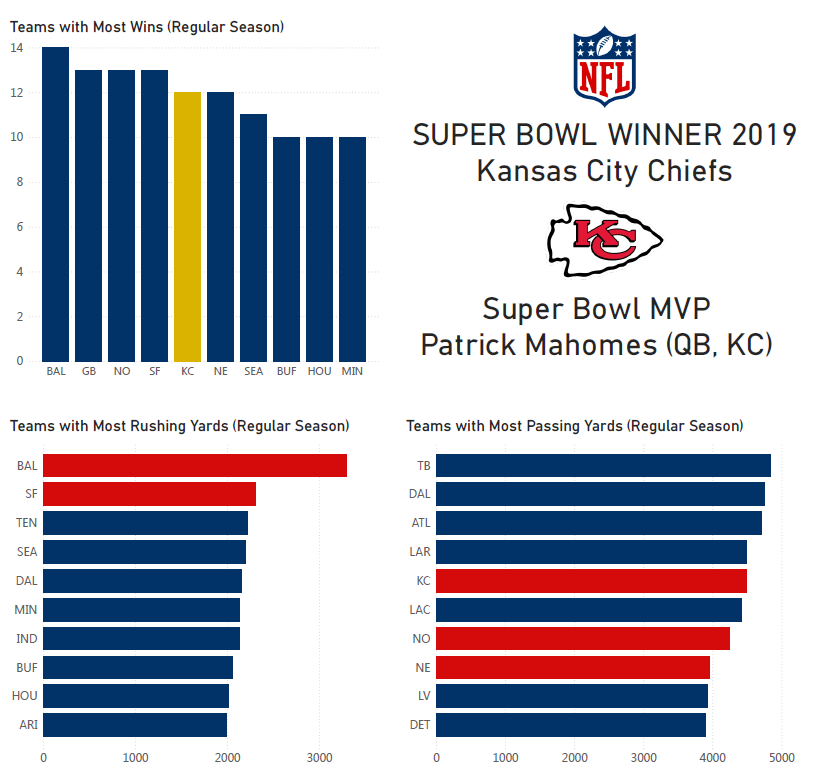
We now know that a new dynasty was born in Kansas City. After 50 years of championship drought, the 2019 season ended with a new successful Super Bowl hunt for the Chiefs.
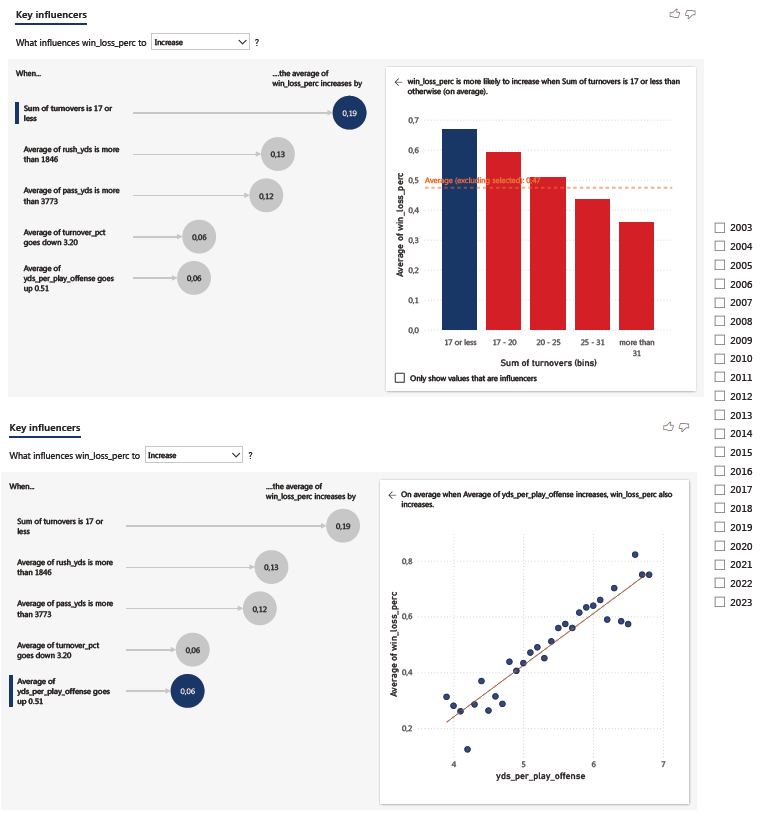
The old NFL saying goes “offense wins games, defense wins championships”. In this analysis, we mostly focused on offensive plays. But to give you an idea of the complexity, here are a few factors that could influence wins on offense side.
It’s not only the trophy the winning team takes home: all team members receive a special Super Bowl ring to commemorate the championship. This is why contending for the Super Bowl is informally referred to as “going for the ring”.
 Back to Project List
Back to Project List
Tévedések vígjátéka egy brazil szupermarketben
Főnök, nagy a baj, egy csomó dolgozó nem hozza az elvárt szintet!
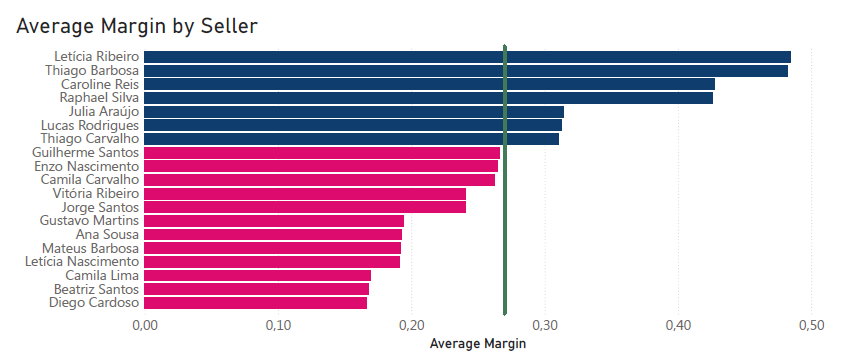
Nálam meg az látszik, hogy teljes részlegek maradnak el az elvárástól!
Mi lesz így velünk?! 😨
Hívjunk papot... vagy adatos embert
Hívjunk papot... vagy adatos embert
Szóval mi történt itt? Az új munkatárs talált a neten egy iparági benchmark profitrátát, és úgy gondolta, szerez néhány jó pontot, ha összeveti a cég teljesítményét ezzel a számértékkel.
A cég éves profitrátájával kezdett, és a benchmark egész jónak tűnt ennek alapján.
A cég éves profitrátájával kezdett, és a benchmark egész jónak tűnt ennek alapján.
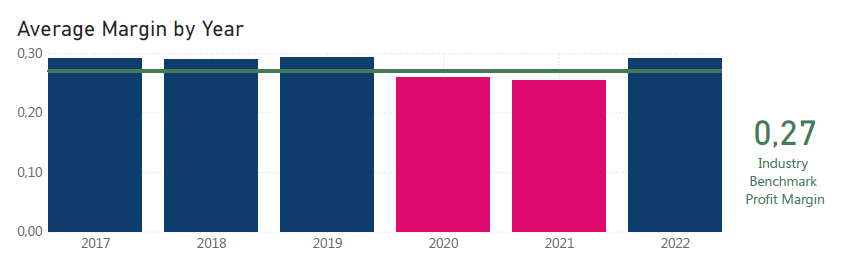
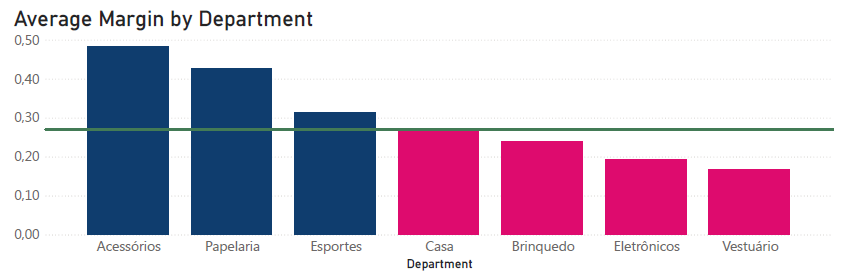
De utána sajnos mélyebbre ment, és ugyanazt az egy számot kereste a különböző áruházi osztályok, sőt az egyes eladók szintjén is.
Ezt már nem kellett volna. Ha kicsit jobban utánanéz, rájött volna, hogy a cégnek külön profitcéljai vannak az egyes részlegek szintjén. Mert tudják jól, hogy más nyereséggel működik a papírosztály és a ruhaosztály például.
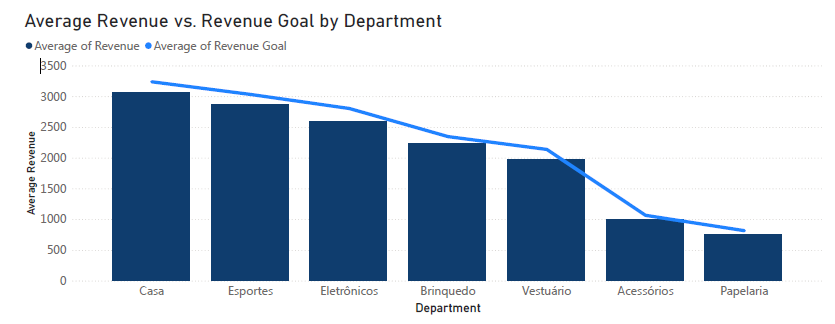
Ha ezekkel a belső adatokkal vetjük össze a teljesítményt, a cég egyenletesen jól teljesít.
Ezt már nem kellett volna. Ha kicsit jobban utánanéz, rájött volna, hogy a cégnek külön profitcéljai vannak az egyes részlegek szintjén. Mert tudják jól, hogy más nyereséggel működik a papírosztály és a ruhaosztály például.
Ha ezekkel a belső adatokkal vetjük össze a teljesítményt, a cég egyenletesen jól teljesít.
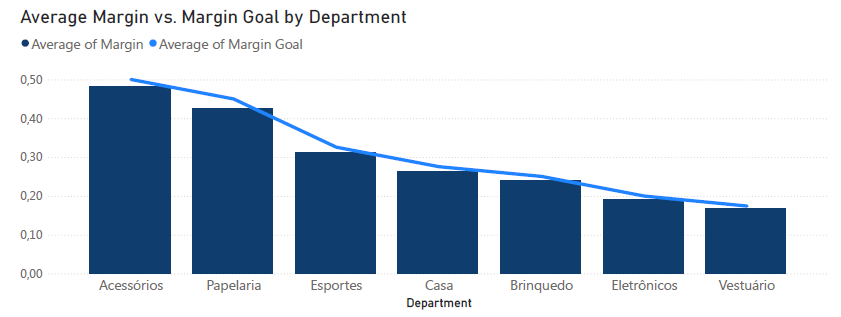
Érdemes megfigyelni, hogy a dolgozók targetjei szépen öröklik az osztályukhoz tartozó értékeket, így minden ugyanaz a célértéke például minden eladónak a játékosztályon.
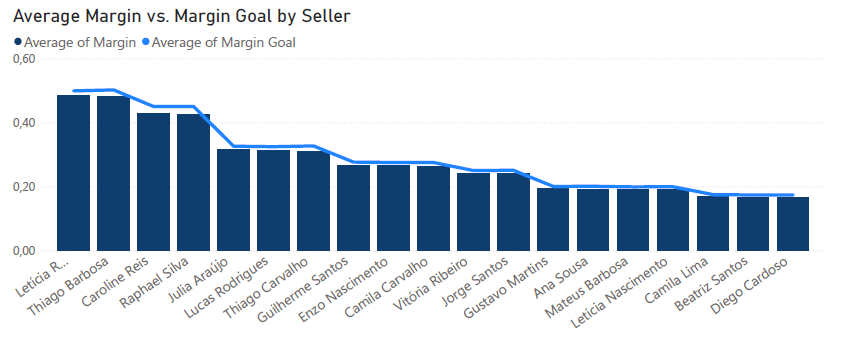
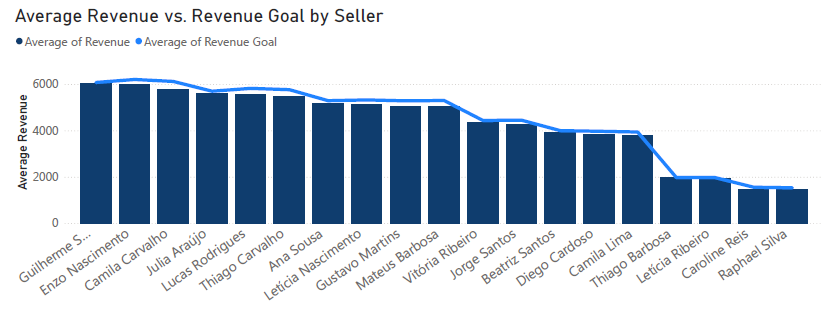
És mielőtt egy újabb hasonló csapdába esnénk, jó tudni, hogy a cégnek gondosan kidolgozott értékesítési céljai is vannak az áruház egyes osztályaihoz. És ezáltal az egyes eladókhoz is.
 Back to Project List
Back to Project List
Vinho Verde – egy jó portugált bort valakinek?
A UCI legendás boros adatsorát elemeztem ebben a projektben. Az eredeti tanulmány (Cortez et al., 2009) már több mint 1200 hivatkozásnál jár. Mivel jelentős 🍾 domain tudással rendelkezem (drága volt, de nagyon szórakoztató 😊), gondoltam, teszek én is egy próbát.

A Vinho Verde nem egy szőlőfajta, hanem egy borvidék és egy borkészítési stílus kombinációját jelenti Portugáliában. Frissen, hosszú érlelés nélkül fogyasztandó borok gyűjtőneve, amelyek között rozé és vörösbor is lehet.
Az eredeti tanulmánytól eltérőn én mindenesetre különválasztottam a két adatkészletet, és csak a fehérborokkal foglalkoztam. Nézzünk rá az adatokra:
Az eredeti tanulmánytól eltérőn én mindenesetre különválasztottam a két adatkészletet, és csak a fehérborokkal foglalkoztam. Nézzünk rá az adatokra:

Amint egy ilyen híres adatsortól várható, nincsenek hiányzó értékek és hasonló problémák. Az adatok tehát 11 pontosan mérhető borkémiai értéket tartalmaznak, és a 12. oszlop tartalmazza a bor minőségi pontszámát, amelyet érzékszervi bírálat (aka kóstolás 😊) alapján kapott.
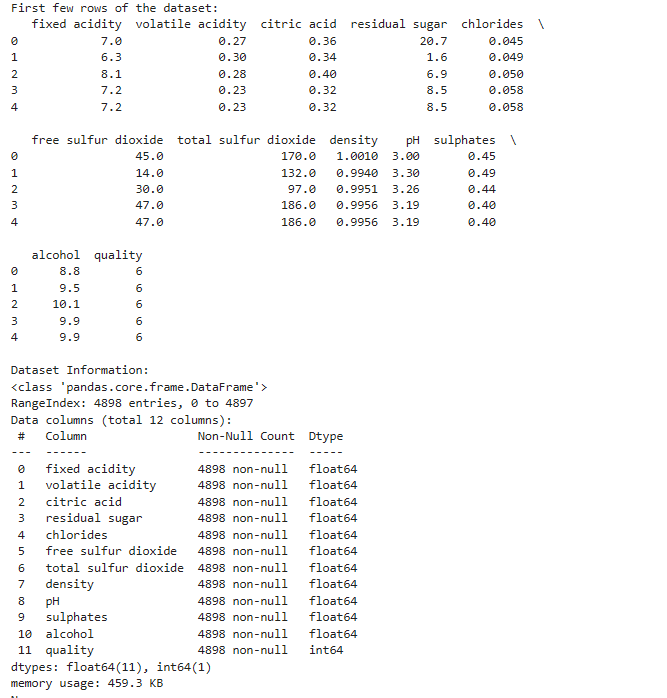
A minőségi pontszámok 3 és 9 közöttiek, a hisztogram tanulsága szerint normál eloszlást követve:
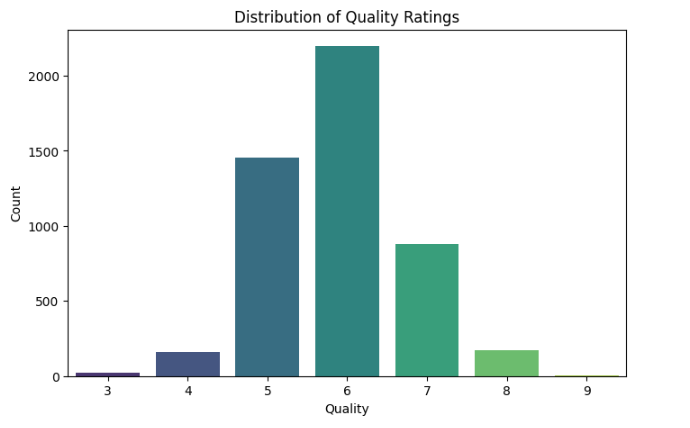
A heatmap megerősíti, hogy van keresnivalónk. Ha elmélyedünk benne, láthatunk néhány logikus, tapasztalatilag is könnyen alátámasztható összefüggést. Például:
a sűrűség és a maradékcukor erősen korrelál
a pH és a titrálható savtartalom (fixed acidity) negatív kapcsolatban áll
az alkoholtartalom látszólag pozitívan hat a minőségre, de ezzel óvatosan kell egyelőre bánni, mert az adatsorban 8.0-tól indul az alkoholtartalom, ami Magyarországon még nagyon nem számít bornak
A tanulmány (és általában minden későbbi vizsgálat) célja egy olyan modell megalkotása volt, amely a mérhető értékek alapján pontos becslést ad a minőségi pontszámra. Ma már azt mondanánk, klasszikus machine learning predikciós probléma. Kezdjük is ezzel:
A Random Forest modell elvégezte a feladatát, de vegyes érzéseink vannak a 0,69-es pontossági értéket látva:
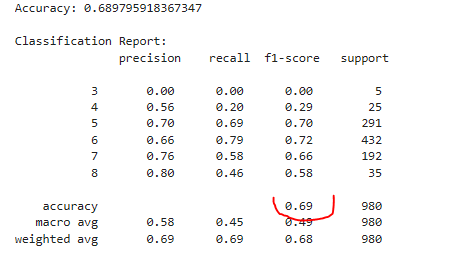
Tegyünk még egy próbát egy AutoML nagyágyúval: enter XGB 🦸. Fontos ugyanakkor figyelembe venni, hogy a minőségi értékeink ordinális változók, miközben a gradient boost folytonos változókra lő. De ezt lehet korrigálni:
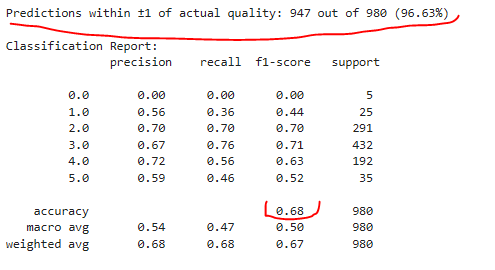
Nos, látható, hogy egy százalékponttal alatta maradtunk a Random Forest Classifier becslési pontosságának. A biztonság kedvéért egyből adtam is egy második esélyt a modellnek, de hiába tűnik ígéretesnek elsőre, hogy 96,63%-os arányban 1 ponton belül becsül... Emlékezzünk vissza a minőségi pontszámok eloszlására: több mint 90%-uk esik az {5, 6, 7} tartományba. Ez így túl könnyű lenne...
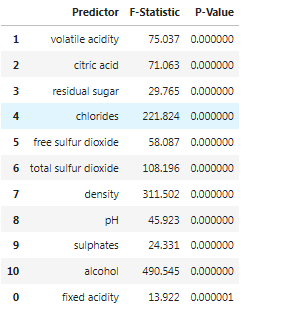
Vegyük elő újra a domain tudást! Van egy olyan tapasztalati sejtésem, hogy a közepes értékek nagyobb hatást gyakorolnak a bor minőségére, mint az alacsony vagy éppen magas értékek. (A túl savas bor kellemetlen, a savmentes meg ugye nem is bor például.) Vizsgáljuk meg ezt, alacsony, közepes és magas értékek csoportját képezve mindegyik borkémiai változónknál, majd varianciaanalízist futtatva:

Az extrém alacsony (több nagyságrenddel 0,05 alatti) p-értékek jelzik, hogy statiszikiailag szignifikáns eltérések vannak a minőség értékében az általunk képzett csoportok között. Más szóval: nagy magabiztosággal elvethetjük az ezzel ellentétes nullhipotézist, miszerint nincs kapcsolat a közepes borkémiai értékek és a minőség között.
Ábrázoljuk most akkor az összefüggéseket a képzett csoportjaink (binjeink) szerint:
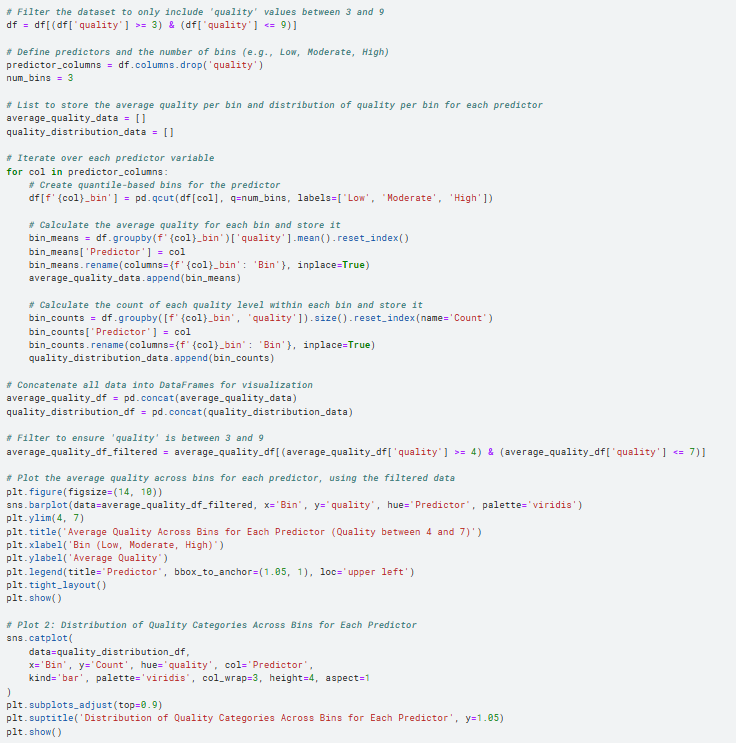
Most sem látunk kiugró eltéréseket, ami újra rávilágít a probléma megoldásának nehézségére, különösen az általánosan alkalmazott regressziós modellekkel.
De megállapíthatjuk például, hogy:
a magasabb alkohol tényleg pozitívan hat a minőségre (így a csoportképzés után már bátran kijelenthető), és szintén pozitív hatása van a magasabb szulfáttartalomnak (a fehérborokra ez jellemző), valamint a magasabb pH-nak (bár megjegyzendő, hogy a pH értéktartománya elég kicsi)
az empirikusan várt közepes értékek, amelyek az egyensúlyért felelnének, csalódást keltőek: csak a maradékcukor, a citromsav és a kén-dioxid mutatók tartoznak ide (utóbbiak össze is függenek egymással)
amiből az alacsonyat keressük, az a teljes titrálható savtartalom, az illósav-tartalom (klasszikus borhiba az illós), a klorid, valamint a sűrűség (mint az alkoholtartalommal fordítottan korreláló faktor)
 Back to Project List
Back to Project List



 Back to Project List
Back to Project List
De megállapíthatjuk például, hogy:
Back to Project List
Book4U – Recommender
I remember the early days of World Wide Web, when everyone talked about this novel feature of an emerging online bookstore. They could actually suggest interesting titles based on your interests and those of other users!
We all know where Amazon has evolved since. And recommender systems or recommendation engines are now part of every webshop.
We all know where Amazon has evolved since. And recommender systems or recommendation engines are now part of every webshop.
And technology has followed along: Python now has some powerful libraries that create a recommender model with robust built-in features. You of course need good quality data, and I was lucky enough to find a set.1
1. https://www.kaggle.com/datasets/arashnic/book-recommendation-dataset
1. https://www.kaggle.com/datasets/arashnic/book-recommendation-dataset
We have three tables: book data, user data and ratings data. We are able to establish a connection between the tables, and actually tell which titles a user rated.
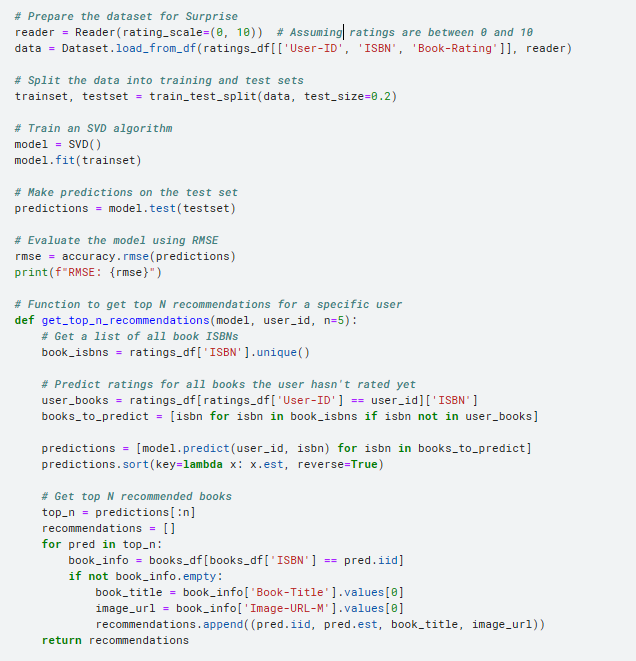
Technically, a recommender can be based on the user’s own preferences (User-Based Collaborative Filtering), or follow along other user’s based on the item just selected (Item-Based Collaborative Filtering). And the Surprise Python library can actually combine these two in it’s SVD model. It also auto-filters it’s predictions with root mean squared error (RMSE) control.
I have set up the notebook to select a random user at every run, and recommend 5 books.
A recommendation would look like this:
Back to Project List